引言:大模型部署工具的百花齐放
让一个大模型跑起来,远不止 pip install 和 model.generate() 那么简单。从底层计算框架到上层服务接口,整个技术栈错综复杂,包含各种各样百花齐放的工具。笔者在刚开始学习这方面的知识时被各种五花八门的工具搞的眼花缭乱,为此,特意进行了整理并写成了本文章
本文将带你自底向上系统梳理当前主流的大模型部署工具链,这也是互联网上难得的对大模型部署工具进行系统梳理的文章。
一、硬件抽象层
在探讨大语言模型的部署时,我们首先需要关注的是底层的硬件支持。硬件抽象层是整个技术栈的基石,它提供了必要的计算资源和驱动支持,使得上层的应用能够高效运行。
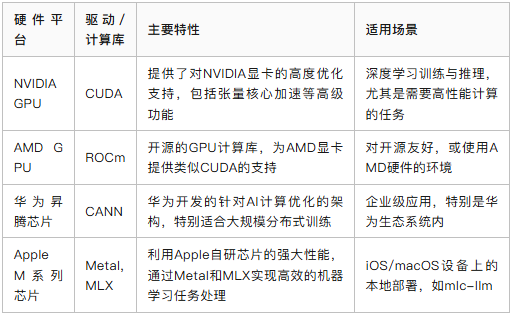
一些主流的硬件平台如下:
- NVIDIA GPU:通过CUDA提供对NVIDIA显卡的高度优化支持,包括张量核心加速等高级功能,非常适合深度学习训练与推理任务。
- AMD GPU:ROCm是一个开源的GPU计算库,为AMD显卡提供类似CUDA的支持,适合那些对开源友好或使用AMD硬件的环境。
- 华为昇腾芯片:CANN是由华为开发的针对AI计算优化的架构,特别适用于大规模分布式训练的企业级应用。
- Apple M系列芯片:利用Apple自研芯片的强大性能,通过Metal和MLX框架实现高效的机器学习任务处理,非常适合iOS/macOS设备上的本地部署。
二、深度学习通用计算框架
深度学习通用计算框架提供张量计算与自动微分。这些框架是所有 AI 模型的基石,不仅服务于 LLM,也支撑着 CV、语音、推荐等任务。
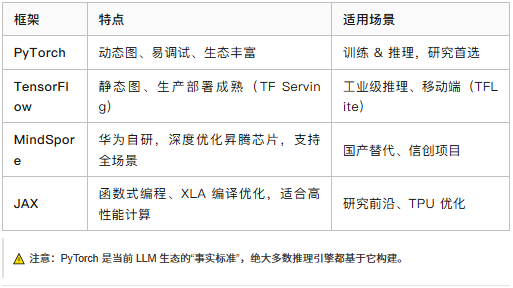
一些主流的计算框架如下:
- PyTorch:作为当前AI研究和开发的事实性标准,PyTorch提供了动态图机制,易于调试,并且拥有丰富的生态系统。
- TensorFlow:以其生产部署成熟度著称,特别是在TF Serving方面表现突出,同时也有针对移动端的TFLite版本。
- MindSpore:由华为开发,专为昇腾芯片优化,支持全场景AI计算,是国内替代方案的一个重要选择。
- JAX:采用函数式编程风格,XLA编译优化使其在高性能计算领域表现出色,尤其是在TPU上。
三、专用推理引擎(性能导向)
当模型进入推理阶段,通用框架的性能往往不够。这时,就需要专门的推理引擎来优化吞吐、降低延迟、减少显存占用。它们通常不提供训练能力,但针对推理性能做了深度优化。
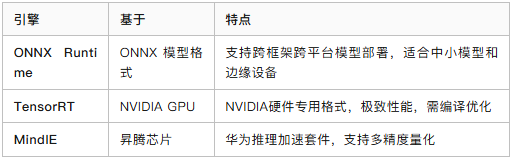
1. 通用推理加速引擎
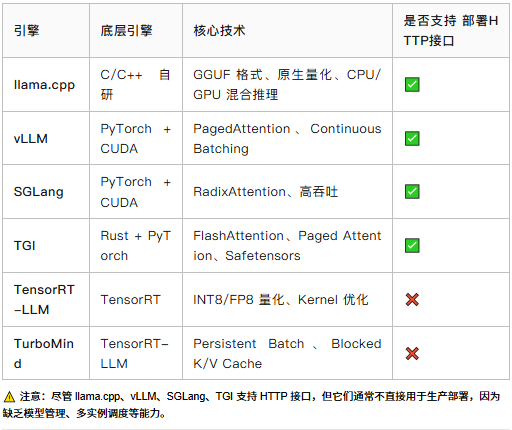
2. LLM 专用推理引擎
- llama.cpp 用纯 C/C++ 实现,支持在 MacBook、树莓派上运行 7B 模型,是个人用户的首选。
- vLLM 是当前最流行的高性能推理引擎,其 PagedAttention 技术像操作系统管理内存一样管理显存,极大提升吞吐。
- SGLang 是 vLLM 的强劲对手,采用 RadixAttention,在某些场景下性能更优。
- TGI(text-generation-inference) 由 Hugging Face 开发,用 Rust 编写,稳定性强,适合工业级部署。
- TensorRT-LLM 是英伟达对大模型的“官方回答”,性能极致,但需编译,灵活性低。
- TurboMind 由上海 AI Lab 开发,基于 TensorRT-LLM 进一步优化,据测试性能可达 vLLM 的 1.8 倍。
四、模型服务与部署工具(用户导向)
这一层的目标是简化部署流程,让用户能用一条命令或一个 UI 就启动模型服务。它们通常封装了下层推理引擎,并提供模型下载、管理、API 接口等功能。
一些主流的部署工具如下:
- Ollama 是基于llama.cpp的部署工具,提供模型自动下载(貌似有自己的专用服务器),也是现在在个人玩家中最流行的大模型部署工具,但其不提供图形化管理界面,仅支持命令行操作
- LM Studio 基于llama.cpp的部署工具,支持模型自动下载(从Huggingface等第三方服务器),提供图形化管理界面,无需命令行操作,专注桌面端用户体验
- OpenLLM 是基于vLLM的部署工具,支持模型自动下载(从Huggingface等第三方服务器)、图形化管理界面
- LMDeploy是上海人工智能实验室开发的基于Turbomind的命令行部署工具,支持下载模型(从Huggingface网站下载),但不提供图形化管理界面
- Xinference 是支持多种推理引擎的LLM本地部署工具,包括llama.cpp,Transformers(本质上是对PyTorch的封装),vLLM和SGLang,支持模型自动下载(从Huggingface等第三方服务器)、图形化管理界面
- LocalAI 是支持多种推理引擎的本地大模型部署工具,支持多模态模型,采用go语言编写,轻量化,支持模型自动下载、图形化管理界面
- GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器,支持 vLLM、 Ascend MindIE、llama-box(基于 llama.cpp 和 stable-diffusion.cpp)多种引擎,并提供广泛的模型支持,支持模型自动下载(从Huggingface等第三方服务器),提供强大的图形化工具用于GPU集群管理
- NVIDIA Triton 是NVIDIA开发的推理服务器,可以支持TensorRT-LLM作为推理引擎来进行HTTP服务的部署,同时其也支持PyTorch等多种其他推理引擎,但其不支持模型自动下载,需要手动准备好模型再部署,同时也不提供图形化管理界面
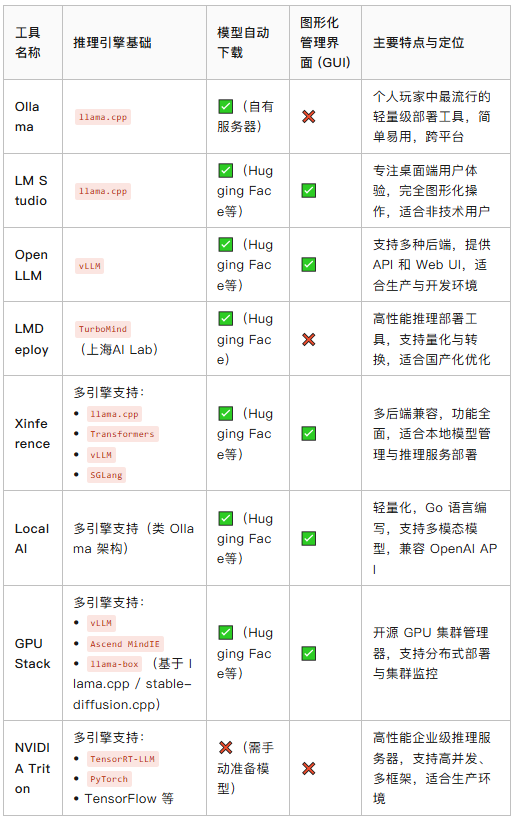
事实上目前推理引擎和模型服务与部署工具这两层在网络上常常被混为一谈,都被称为大模型部署工具,我认为两者的区分主要在于其重点关注的角度,推理引擎是性能导向的,重点关注如何优化性能,模型服务与部署工具则是用户导向,重点关注用户启动和管理服务的易用性
五、模型分发与管理平台
没有模型权重,一切无从谈起。以下平台提供了模型的下载、版本管理和社区支持:
- Hugging Face Hub:全球最大模型仓库,支持 Transformers、TGI、vLLM 等格式。
- ModelScope(魔搭):阿里主导的国产模型平台,支持 MindSpore、LMDeploy 等生态。
- OpenXLab:上海 AI Lab 背景,强调开源开放。
六、总结
从硬件驱动到模型平台,大模型部署已发展成一个层次清晰、分工明确的复杂生态系统。我们可以将其概括为一个 “五层架构”:
- 硬件抽象层:提供算力基础,决定了性能上限。
- 通用计算框架:构建模型的“操作系统”,PyTorch 仍是核心。
- 专用推理引擎:性能优化的“加速器”,针对 LLM 特性深度定制。
- 部署与服务工具:面向用户的“操作界面”,极大降低使用门槛。
- 模型分发平台:模型的“应用商店”,保障生态的开放与共享
大模型部署的门槛正在迅速降低。未来,我们或将看到更多“全栈一体化”的解决方案,进一步模糊各层边界,让“运行一个私有大模型”变得像安装一个普通软件一样简单。而作为开发者,理解这个生态的全景,将帮助你在纷繁的技术中做出更明智的选择。